The 80/20 rule in software development says that the final 20% of a project will take 80% of the total time to build.
Algorithmic tools are designed to make life easier. The new raft of AI systems is a great example of this; tools for translation, image creation, text generation, and more that allow laypeople to do a whole bunch of stuff they never could before with ease and simplicity. But all of these systems share a similar problem: they’re only about 80% of the way there. For the everyday use case that’s all you need! But when these systems shift from helping end users to replacing human professionals the importance of that 20% becomes starkly apparent. This problem is twofold:
- Most people don’t understand the depth of what a professional in that industry does.
- There’s no incentive for the creators of these systems to solve that last 20%, because proportionally it would require 80% of the time/investment to do.
Translation
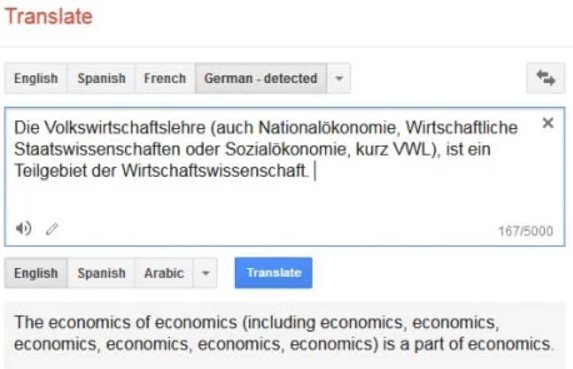
Machine translation systems are great for when you’re travelling abroad and trying to understand a menu or read place names. The ones that take a photo, run it through OCR and replace the foreign text with your preferred language are so handy, even though we’ve all seen they can get a bit rough around the edges. In those cases, you just adjust the camera and try again or work out the intended meaning from context clues. You use human intervention to ensure a good result and make the final decision, rather than explicitly trust the machine output.

An IBM slide from 1979.
But if you’re translating asylum claims with automated tools and using that as your basis for a confirmation or denial of someone’s hope to survive you need that missing 20% functionality to understand the deeper context. This is the kind of work that professional translators excel at, but they’re being supplanted in droves by people who think machine alternatives are Good Enough™️, no matter how many wrongfully denied claims this causes. The twofold problem is apparent here, either:
- The procurement officials' lack of knowledge domain and their simplistic use of such tools means they don’t understand why these systems aren’t good enough, or;
- They don’t want to bear the costs associated with the development of a professionally useful system.
While Hanlon’s razor says the former is probably correct, we also can’t forget that these systems are orders of magnitude cheaper than paying for teams of specialised, skilled staff who understand things that automated tools don’t like minutiae of language, cultural context, translation vs localisation, etc.
Source: @mikilanguages on Twitter (dead account).
Image/Text/Model Generation
I’ve seen friends of mine that are graphic designers or other UI/UX professionals be told they’re skills are becoming useless because of DALL-E, Midjourney, and other generative image systems. The people who praise these tools understand it from their use case of generating pretty pictures. But a graphic designer doesn’t make pictures. They understand the context and branding of the project, they ensure designs fit with the theme and constraints, they build in accessibility in contrast ratios and font choices, they make sure their output can be converted from screen to print, can be scaled and vectorised, and they ensure a consistent visual language across all parts of the project. This is the skill difference between the amateur/hobbyist and the professional, the huge depth and breadth of work that goes into a profession that outsiders don’t see. These are things that AI systems don’t understand.
I’ve seen discussions about AI 3D modelling tools (from text prompt or images) as the next great revolution in gaming but making Maya/Blender models is not what a 3D modeller in game design does. For sure it is a part of their job, just like a graphic designer makes pictures, but it’s only one part. The 3D modeller need to ensure the creation fits in the thematic style of the existing assets, but they also need to care about efficiency. An AI generator that creates a 40,000 polygon couch is a cool novelty, but who will do the retopology to bring it down to an acceptable poly count for inclusion in a game? We have existing simplification algorithms in 3D design and vector art, but they are very limited. They’re a tool that assists experts but the hard work is still there, often half of which can even just be fixing the mistakes of the simplification algorithm. That’s not even getting into efficient UV wrapping, texture packing, or normal map generation, things these tools can’t do not for lack of training data but for lack of R&D into making a tool that specialises in that area.
Outcomes
I doubt any of the aforementioned professions (along with voice actors, copywriters, etc) will completely disappear. But these technologies are used as an excuse to devalue skilled work, reduce their wages, cut their contracts. I have already had friends in copywriting and design who have lost long-standing contracts and retainers thanks to ChatGPT/DALL-E only to be offered piecemeal work at reduced rates to just “tidy up” the output from those tools; a task which often takes more time and effort than if they had been starting from scratch.
More Training Will Fix It
The solution often touted is that “the tools will get better with more training data/computational power!” But this shows a naive understanding of how the technology works. I’ve discussed previously why neither more training data or computational power will solve the accuracy issues of general purpose AI tools, and my comments still stand. But when we talk about implementing these general purpose tools in specialist settings, we come up against the 80/20 barrier. Solving the last 20% of a complex problem would end up costing 80% of the total investment in development and no company has any reason to justify that expense.
Because the average Joe thinks the existing systems are sufficient, they’ve already purchased subscriptions or licenses and are happy with the results. The companies making these tools have already got that market with only 20% of the development cost of an actual system so why would they spend the rest of the 80% if there’s no demand? And because the use cases which cause problems are edge cases, the potential market share gains from trying to perfect it wouldn’t provide a return on investment.
Systems like ChatGPT cost over $700,000 a day on inferencing (producing text) alone, not including the millions spent on training. But that’s still a far cheaper option than trying to develop effective, vetted, properly labelled training data sets and researching how to solve edge cases. Why acquire and license and categorise and tag imagery/music/code/text when you can just crawl the web and use everyone’s data without their permission (while violating license agreements) and just hope your tool doesn’t end up creating accidental CSAM? Why research how to solve problems with racial bias when DALL-E can shadow modify your prompt to include ethnicities where it thinks is appropriate? Why hire linguistic experts and translators to provide supervised feedback for training when you can just use underpaid “ghost labour” who don’t have the skills or support to effectively refine a training dataset?
Update 22/10/2023: A day after I posted this 404 Media dropped the news that the LAION-5B training dataset used for imagery GenAI contains CSAM.
Hope
If there’s one benefit to rising interest rates it’s that tech investment may get more cautious. Throwing large amounts of cash after startups that are unlikely to ever turn a product profit is a lot harder to justify as the zero interest rate era dies out so we might see less half-baked tools that cost as much in software/hardware as they do in wages. The major competing platforms will probably feel the pinch and raise their prices which could make them less attractive compared to trained professionals who can do the whole job instead of just a bit of it. And given how expensive so many of these systems are to develop, train, and maintain, a few might eventually shutter as the hype surrounding them dies down.
It’d also be nice to see more regulation as the dangers of such systems become apparent. There’s been some success in limiting the use of facial recognition systems without oversight and if the trend continues we may see regulation looking into generative AI too.
]]>